
알라딘 중고서점 가격 일괄 스크래핑
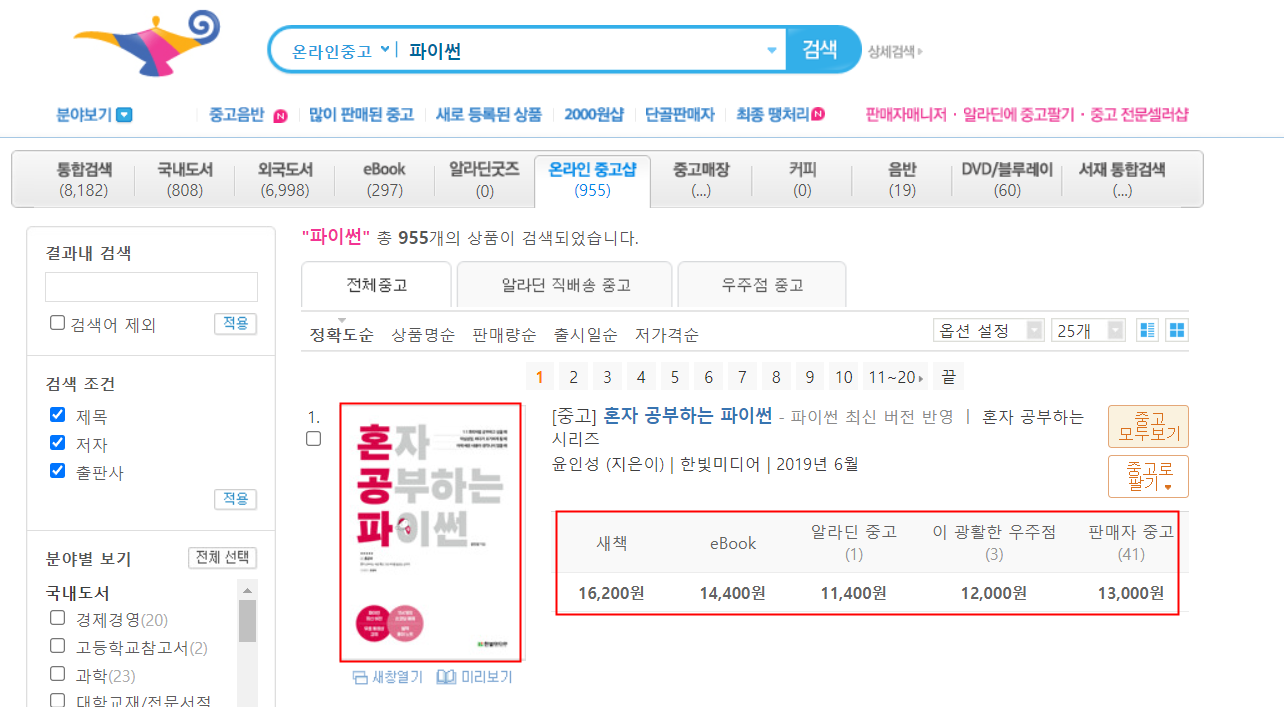
1. 원하는 책 제목 검색
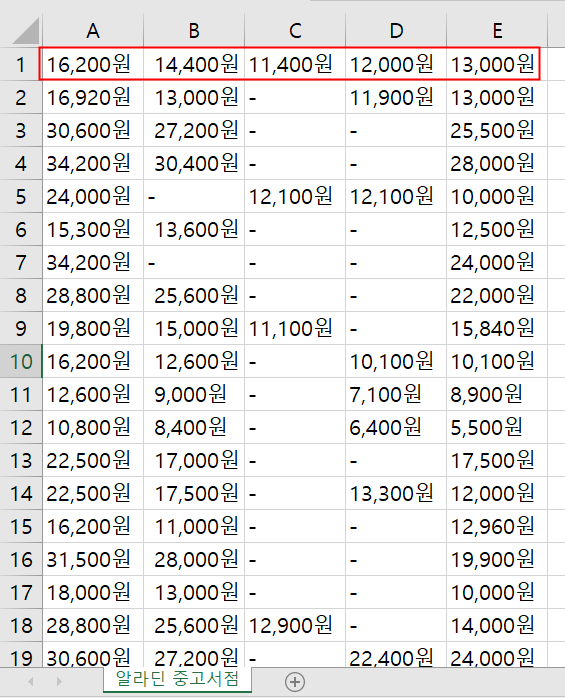
2. 다섯가지 종류의 가격과 책 표지, 제목을 긁어서
3. 엑셀에 표현.
(표지) 책제목 새책 eBook 알라딘 광활.. 판매자 중고
(그림) 혼자공부하는 파이썬 16300원 14400원 11400원 12000원 13000원
(그림) .........
# 가격만 가져오는 프로그램
import urllib.request as req
from bs4 import BeautifulSoup
page_num = 1
'''
엑셀 파일을 생성하는 부분 추가될 곳
'''
while True:
url = "https://www.aladin.co.kr/search/wsearchresult.aspx?SearchTarget=Used&KeyWord=%ED%8C%8C%EC%9D%B4%EC%8D%AC&KeyRecentPublish=0&OutStock=0&ViewType=Detail&SortOrder=11&CustReviewCount=0&CustReviewRank=0&KeyFullWord=%ED%8C%8C%EC%9D%B4%EC%8D%AC&KeyLastWord=%ED%8C%8C%EC%9D%B4%EC%8D%AC&CategorySearch=&chkKeyTitle=&chkKeyAuthor=&chkKeyPublisher=&ViewRowCount=25&page={}".format(
page_num)
html_code = req.urlopen(url)
soup = BeautifulSoup(html_code, "html.parser")
# title = soup.select("a.bo3>b")
# print(title) #출력결과: [<b>혼자 공부하는 파이썬</b>, <b>Do it! 점프 투 파이썬</b>, <b>이것이 취업을 위한 코딩 테스트다 with 파이썬</b>,...]
books = soup.find_all("div",{"class":"ss_book_box"})
for book in books:
# price = book.find_all("a", {"class":"bo_used"}).find_all 판매분류와 가격이 한번에 뽑힌다.
price = book.select("tr>td>a.bo_used")
print(price)
# page_num += 1
# if len(title) == 0:
break위 코드는 얼핏보면 가격만 잘 긁어오는 것처럼 보이지만, 알고보면 엉터리 코드다.
첫번째 책에 가격이 다섯가지 종류가 있는데, 나중에 제목과 가격을 출력할 때 이를 고려하지 않고,
책1, 책1의 가격1
책2, 책1의 가격2
책3, 책1의 가격3
...
이런 식으로 출력이 된다. 오류가 나지 않아도 확인을 해보면 쉽게 알 수 있다.
데이터를 다룰때는 내가 할애할 에너지의 30%정도는 남겨두고, 1차 완성 후에 직접 실행하며 결함이 없는지 확인하는 과정도 중요하다.
문제는, 이거를 고치다가 참 많은 오류가 났다.
가격을 틀리지 않고 제대로 가져온 코드는 여기에 있다.
import urllib.request as req
from bs4 import BeautifulSoup
import openpyxl
import os
page_num = 1
# 엑셀 파일 만들거나 가져오기
filename = './알라딘 중고서점.xlsx'
if not os.path.exists(filename):
wb = openpyxl.Workbook()
wb.active.title = "알라딘 중고서점"
wb.save(filename)
else:
wb = openpyxl.load_workbook(filename)
sheet = wb.active
url = "https://www.aladin.co.kr/search/wsearchresult.aspx?SearchTarget=Used&KeyWord=%ED%8C%8C%EC%9D%B4%EC%8D%AC&KeyRecentPublish=0&OutStock=0&ViewType=Detail&SortOrder=11&CustReviewCount=0&CustReviewRank=0&KeyFullWord=%ED%8C%8C%EC%9D%B4%EC%8D%AC&KeyLastWord=%ED%8C%8C%EC%9D%B4%EC%8D%AC&CategorySearch=&chkKeyTitle=&chkKeyAuthor=&chkKeyPublisher=&ViewRowCount=25&page={}".format(
page_num)
html_code = req.urlopen(url)
soup = BeautifulSoup(html_code, "html.parser")
books = soup.find_all("div",{"class":"ss_book_box"})
for i, book in enumerate(books):
# price = book.find_all("a", {"class":"bo_used"}).find_all 판매분류와 가격이 한번에 뽑힌다.
price = book.select("table > tr > td")[2].select("table.usedtable01 > tr > td")
for index, seller in enumerate(price):
print(seller.string)
sheet.cell(row=i+1, column=index+1, value=seller.string)
# print(books)
# print(title)
# price = soup.select("a.bo_used>b")
# for i, j in zip(title, price):
# # print(i.string, j.string)
# f.write(i.string+","+j.string+"\n")
# page_num += 1
# if len(title) == 0:
# break
wb.save(filename)
wb.close()
# for page_num in range(1,5):
# html_code = req.urlopen(url.format(page_num))
'파이썬 공부 > 기초' 카테고리의 다른 글
| 파이썬 이중콜론 :: 의미 (0) | 2022.06.02 |
|---|---|
| The current PyTorch install supports CUDA capabilities sm_37 sm_50 sm_60 sm_61 sm_70 sm_75 compute_37 에러 (0) | 2022.03.01 |
| [python] 알라딘 중고서점 스크래핑-3 (0) | 2021.12.21 |
| [python] 알라딘 중고서점 스크래핑-2 (0) | 2021.12.21 |
| 리스트 옮기기(파이썬) (0) | 2021.01.20 |
알라딘 중고서점 가격 일괄 스크래핑
1. 원하는 책 제목 검색
2. 다섯가지 종류의 가격과 책 표지, 제목을 긁어서
3. 엑셀에 표현.
(표지) 책제목 새책 eBook 알라딘 광활.. 판매자 중고
(그림) 혼자공부하는 파이썬 16300원 14400원 11400원 12000원 13000원
(그림) .........
# 가격만 가져오는 프로그램
import urllib.request as req
from bs4 import BeautifulSoup
page_num = 1
'''
엑셀 파일을 생성하는 부분 추가될 곳
'''
while True:
url = "https://www.aladin.co.kr/search/wsearchresult.aspx?SearchTarget=Used&KeyWord=%ED%8C%8C%EC%9D%B4%EC%8D%AC&KeyRecentPublish=0&OutStock=0&ViewType=Detail&SortOrder=11&CustReviewCount=0&CustReviewRank=0&KeyFullWord=%ED%8C%8C%EC%9D%B4%EC%8D%AC&KeyLastWord=%ED%8C%8C%EC%9D%B4%EC%8D%AC&CategorySearch=&chkKeyTitle=&chkKeyAuthor=&chkKeyPublisher=&ViewRowCount=25&page={}".format(
page_num)
html_code = req.urlopen(url)
soup = BeautifulSoup(html_code, "html.parser")
# title = soup.select("a.bo3>b")
# print(title) #출력결과: [<b>혼자 공부하는 파이썬</b>, <b>Do it! 점프 투 파이썬</b>, <b>이것이 취업을 위한 코딩 테스트다 with 파이썬</b>,...]
books = soup.find_all("div",{"class":"ss_book_box"})
for book in books:
# price = book.find_all("a", {"class":"bo_used"}).find_all 판매분류와 가격이 한번에 뽑힌다.
price = book.select("tr>td>a.bo_used")
print(price)
# page_num += 1
# if len(title) == 0:
break위 코드는 얼핏보면 가격만 잘 긁어오는 것처럼 보이지만, 알고보면 엉터리 코드다.
첫번째 책에 가격이 다섯가지 종류가 있는데, 나중에 제목과 가격을 출력할 때 이를 고려하지 않고,
책1, 책1의 가격1
책2, 책1의 가격2
책3, 책1의 가격3
...
이런 식으로 출력이 된다. 오류가 나지 않아도 확인을 해보면 쉽게 알 수 있다.
데이터를 다룰때는 내가 할애할 에너지의 30%정도는 남겨두고, 1차 완성 후에 직접 실행하며 결함이 없는지 확인하는 과정도 중요하다.
문제는, 이거를 고치다가 참 많은 오류가 났다.
가격을 틀리지 않고 제대로 가져온 코드는 여기에 있다.
import urllib.request as req
from bs4 import BeautifulSoup
import openpyxl
import os
page_num = 1
# 엑셀 파일 만들거나 가져오기
filename = './알라딘 중고서점.xlsx'
if not os.path.exists(filename):
wb = openpyxl.Workbook()
wb.active.title = "알라딘 중고서점"
wb.save(filename)
else:
wb = openpyxl.load_workbook(filename)
sheet = wb.active
url = "https://www.aladin.co.kr/search/wsearchresult.aspx?SearchTarget=Used&KeyWord=%ED%8C%8C%EC%9D%B4%EC%8D%AC&KeyRecentPublish=0&OutStock=0&ViewType=Detail&SortOrder=11&CustReviewCount=0&CustReviewRank=0&KeyFullWord=%ED%8C%8C%EC%9D%B4%EC%8D%AC&KeyLastWord=%ED%8C%8C%EC%9D%B4%EC%8D%AC&CategorySearch=&chkKeyTitle=&chkKeyAuthor=&chkKeyPublisher=&ViewRowCount=25&page={}".format(
page_num)
html_code = req.urlopen(url)
soup = BeautifulSoup(html_code, "html.parser")
books = soup.find_all("div",{"class":"ss_book_box"})
for i, book in enumerate(books):
# price = book.find_all("a", {"class":"bo_used"}).find_all 판매분류와 가격이 한번에 뽑힌다.
price = book.select("table > tr > td")[2].select("table.usedtable01 > tr > td")
for index, seller in enumerate(price):
print(seller.string)
sheet.cell(row=i+1, column=index+1, value=seller.string)
# print(books)
# print(title)
# price = soup.select("a.bo_used>b")
# for i, j in zip(title, price):
# # print(i.string, j.string)
# f.write(i.string+","+j.string+"\n")
# page_num += 1
# if len(title) == 0:
# break
wb.save(filename)
wb.close()
# for page_num in range(1,5):
# html_code = req.urlopen(url.format(page_num))
'파이썬 공부 > 기초' 카테고리의 다른 글
| 파이썬 이중콜론 :: 의미 (0) | 2022.06.02 |
|---|---|
| The current PyTorch install supports CUDA capabilities sm_37 sm_50 sm_60 sm_61 sm_70 sm_75 compute_37 에러 (0) | 2022.03.01 |
| [python] 알라딘 중고서점 스크래핑-3 (0) | 2021.12.21 |
| [python] 알라딘 중고서점 스크래핑-2 (0) | 2021.12.21 |
| 리스트 옮기기(파이썬) (0) | 2021.01.20 |